Because email remains the most ubiquitous form of business communication, it continues to be a favorite attack vector for cybercriminals. Email has always been vulnerable because it was not originally designed with security or privacy in mind. As a result, email security vendors emerged to protect this critical communication channel. In the early days, many vendors used signature or reputation-based detection technologies, which later evolved into sandboxing and dynamic analysis and, for a time, were very effective. Unfortunately, cybercriminals have been evolving faster than the solutions built to block them, and now the current approaches to email security are significantly less effective.
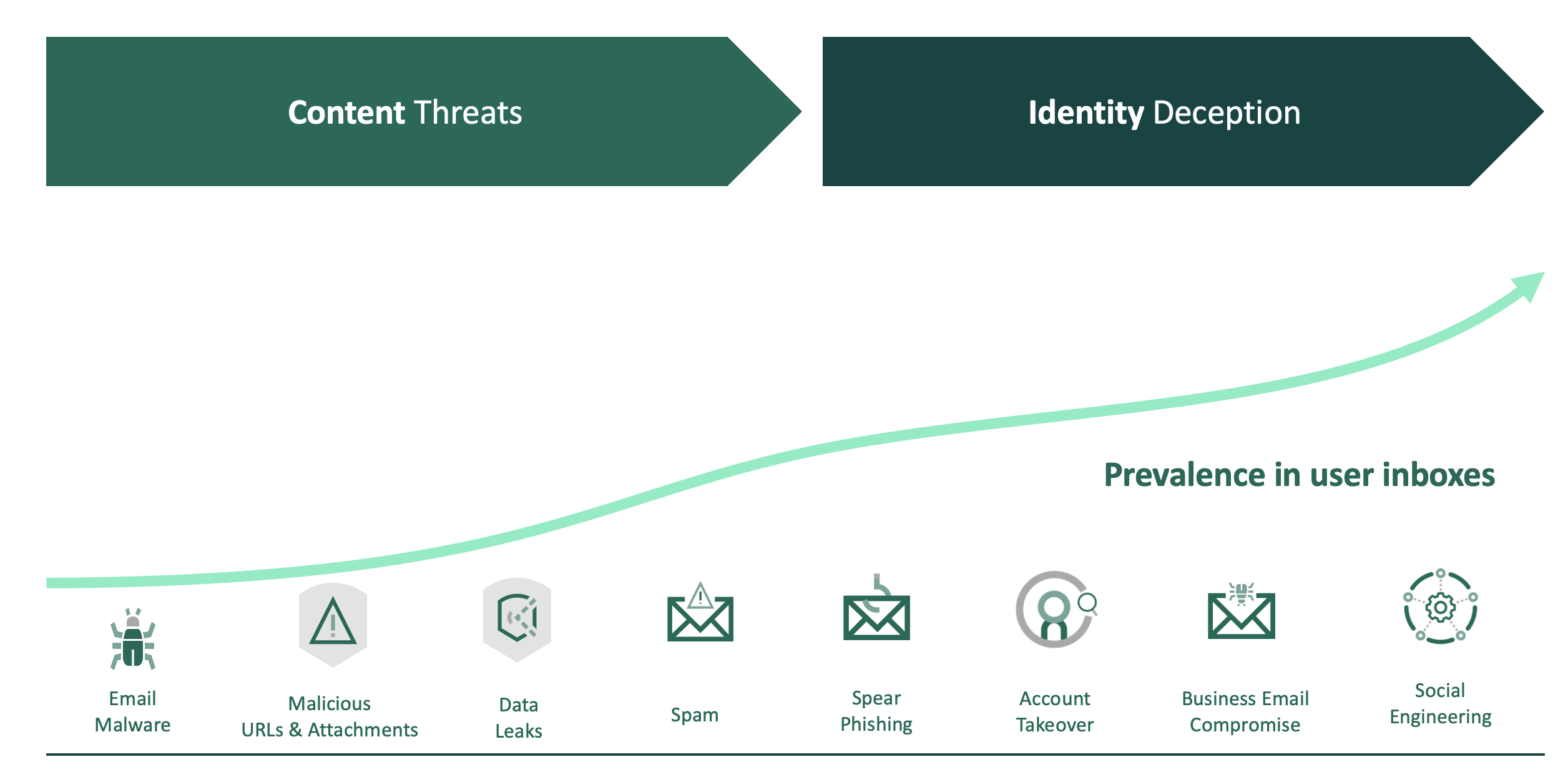
Over the last few years, cybercriminals have shifted their focus from sending “trusted” content to deceive a system to practicing identity deception to deceive a person into thinking an email message is trusted. Existing approaches focus largely on inspecting message content and assessing the reputation of the servers the message came from. Cybercriminals understand this paradigm and changed the primary vector of attack to use impersonation tactics to convince the recipient to take the requested action.
A New Day, A New Email Threat
Today’s modern email attacks inherently use identity deception to circumvent existing email defenses, such as SEGs. The key to an identity deception-based attack is impersonation, where the attacker sends a message that seems to come from a known identity—an individual, organization, or brand that is trusted by the recipient—to convince him or her to take action, such as completing a wire transfer or disclosing sensitive data. In addition, most attacks leverage evasive techniques, such as launching the attack from a reputable email service like Gmail or Outlook, leveraging pretext to increase trust and then deploying sandbox-aware malware or even no malicious content or payload at all. These attacks are multiplying and are increasing the likelihood of causing financial and reputational damage, often with C-level or even boardroom-level ramifications.
The most common form of identity deception is a Display Name Attack. Since common consumer mailbox services such as Gmail, Yahoo!, and Outlook allow a user to specify any value in the display name portion of the "FROM" header, an attacker can simply insert the identity of a trusted individual, such as the CEO, or a trusted brand, such as the bank that the recipient uses into the display name field, making this type of attack simple and cheap to stage.
Another type of deception is a domain spoof where attackers try to gain the trust of the victim by spoofing the recipient’s own domain using a lookalike domain, or in a much more advanced and malicious scenario as an Account Takeover (ATO)-based attack, by compromising a legitimate, previously established email account and then using it to launch the targeted attack.
Email Security for the Next-Gen: Not When or How, But NOW!
In response to the shortcomings of current email security solutions to combat these types of attacks, Fortra has developed a unique approach by leveraging advanced data science. The data science behind Fortra's Cloud Email Protection is an advanced system of AI-powered machine learning (ML) models that work together to accurately detect impersonation and social engineering techniques used in messages. Fortra’s Advanced Data Science team is comprised of a storied roster of email impersonation and threat intelligence researchers spanning Agari, Clearswift, PhishLabs, and other Email Security solutions.
This robust team possesses a comprehensive wealth of email security domain expertise to develop high-performing machine learning models that consider parts of messages both individually and collectively. These models are combined using ensemble learning techniques that relate them to one another to consider all threat characteristics and patterns. Together, they maximize decision confidence and ensure accuracy.
How Does Machine Learning in Cybersecurity Work?
To best explain how the data science works behind the scenes, it is important to break down the parts of a message that are analyzed and how the machine learning models are applied–this includes the various components embedded in email header data, including:
“From” field, or Sender Display Name
"To" field, or Recipient Display Name
Subject Line
Local Part, or Email Prefix (see image below)
Email Sending Domain of Webmail Address (see image below)

In addition, the models scan any contextual data like text and metadata. These include:
The sender’s infrastructure
The number of days IP address has been used to send from on behalf of domain
The number of emails sent using the same Local Part of email
The number of emails using the same Display Name
Intent of the email (examine nature of content, like Subject Line)
Matching Address Group and Display Name
Character text used in the Local Part of email (Latin vs. Cyrillic)
SPF/DKIM/DMARC records
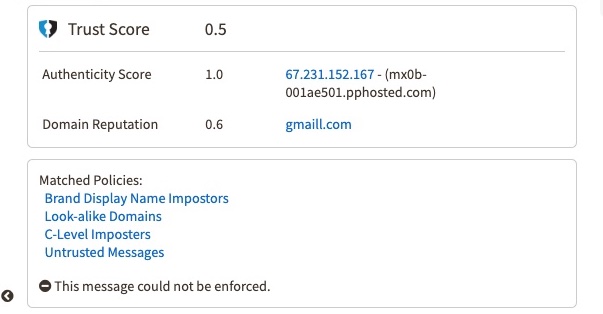
Once all of this data is evaluated and scored, Cloud Email Protection produces Reputation and Authenticity scores. This basically determines if the email was part of a previously unidentified targeted attack, or if it was simply an anomaly. For example, if there was an email that received a very low Authenticity score but a high Reputational score, the models would suggest that there was likely a spoof of a highly reputed domain. The models will then output a “final” score based on the unique combination between the two model scores in the customer’s UI dashboard.
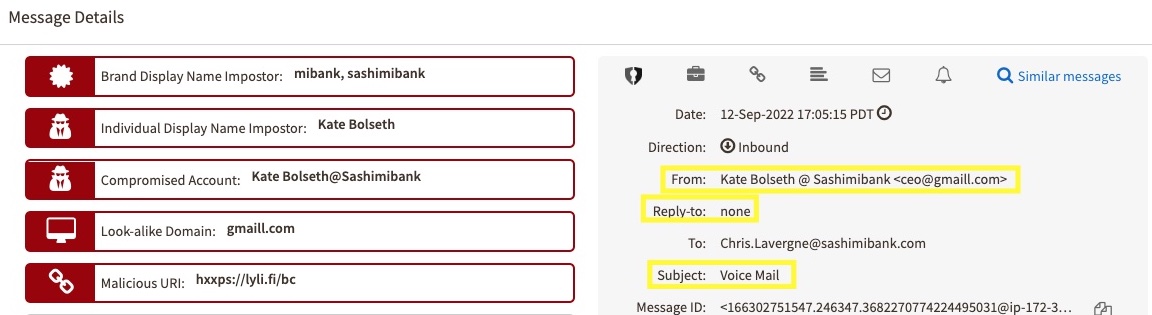
In the below example of Kate Bolseth@SashimiBank below, the threat actor used a lookalike domain for Gmail (gmaill.com>) with a generic Local Part/prefix (<ceo), which would generally be missed by the naked eye. However, Fortra's machine learning models caught it via the identified policies listed and gave it an overall low trust score of 0.5 based on the combination of a low authenticity score, as well as the poor domain reputation of gmaill.com, as shown by the below:
Though every machine learning paradigm has strengths and weaknesses, it continues to push forward and create opportunities to perform tasks more accurately and efficiently. For these reasons, it is critical to understand the task objective and select the ideal machine learning paradigm to perform the task well. This is especially true for applications of machine learning that can impact the operation of business processes, which could potentially bottleneck the flow of inbound and outbound communications. This is why Cloud Email Protection leverages a pre-train and fine-tune paradigm, adapting pragmatic pre-trained models to various downstream tasks, like:
Analyzing specific text-based email components, such as Subject Lines and body content
Task-specific functions, such as determining message type or level of suspiciousness
Identifying groupings or clusters in email data
Creating data lakes with labeled data that can be used by other models
Ingesting feeds of useful data–like lists of suspicious domains and IP address groups
AI is no longer the future of email security; it is the present. Traditional email defenses struggle to detect impersonation and social engineering, allowing BEC and credential theft attacks to reach user inboxes at an alarming rate. Stopping these threats at enterprise scale demands the use of data science to determine whether messages should be trusted.
This is where Fortra's Cloud Email Protection is at the forefront–driving state-of-the-art data science with cutting-edge research on emerging known and unknown email threats. We know how modern email threats work inside and out, and we use that insight to design robust models that can detect these threats in the most challenging enterprise environments.