Snowflakes and Early Automation Efforts
At Agari, as part of our mission to solve phishing, we deal with data at scale. We’ve chosen AWS to help us move quickly, making sure our infrastructure is as agile as we are.
Unfortunately, in the beginning, we treated AWS instances much the same way as physical servers: each configuration was lovingly hand-crafted, packages were installed at the command line with artisanal care. We were, in short, server-huggers.
That had to change. The only way we were going to truly leverage the strengths of a cloud infrastructure was to embrace the world of infrastructure-as-code and ephemeral servers that could be created and destroyed at will. Our first attempt at this involved an external contractor, Chef, berkshelf, and many tears. The project was never entirely completed and left us in a worse state than pre-automation, particularly because there wasn’t enough institutional knowledge of the system.
Ansible

After wrestling with this for about a month, in an effort to determine whether I could overhaul the existing Chef codebase, I introduced Ansible as a potential replacement. A significant point in favor of Ansible was that the learning curve for being able to use it effectively is quite gentle. The simple, declarative configuration syntax made it very easy to get the rest of the team using it. Our first big win was replacing our ElasticSearch cookbook with an Ansible playbook. Comparing the two repositories, the original Chef cookbook is around seven times as many lines of code. Best of all, we had almost immediate success in getting a few other software engineers at Agari interested in contributing to the Ansible repository.
One of the big things we learned from implementing the ElasticSearch playbook was that we needed to make sure our playbooks were as modular as possible. The first step was creating a base role that was vetted for use on legacy hosts. This role handles things like user management, sshd and sudo configurations, log rotation, etc. This enabled us to shut down the Chef server and move forward confidently while continuing down the road to full automation.
Ansible Vault
One of the other major features we needed at this stage was a way of securely managing and distributing secrets. We choose Ansible Vault as an encrypted key-value store for things like API keys, SSL private keys and the like. We’ve been utilizing LastPass Enterprise to manage shared passphrases, including the Vault passphrase.
group_vars and environment-specific configuration details
One of the more challenging issues we’ve faced with deploying Ansible has been managing per-environment variables. Our early attempts revolved around use of inventory domains and group_vars which would apply in specific contexts. However, we ran into a whole host of issues with provisioning with both Vagrant and Terraform, when first instantiating instances, the environment distinctions are difficult to make apparent to Ansible. The most useful thing we came up with was a 00_init.yml file in group_vars/all with the following:inventory_domain: '{{ inventory_hostname | replace(inventory_hostname_short ~ ".", "") }}'
This allows us, given standard naming conventions, to know which environment we are in, what function the instance should be serving and which product this instance is being utilized for. I’ve always been a proponent of human-readable functionally-based hostnames and this has been perhaps the best example of how and why that can pay off. So to illustrate what I mean, given a hostname of app-00.cp.stage.agari.com we can infer that this is the first application server in the Customer Protect (CP) staging environment. Our templates can then be customized per product and environment as well as by host roles.
Vagrant
Our early provisioning system relied on some custom glue code and Vagrant's AWS provisioner. This worked okay, but Hashicorp was already starting to transition away from Vagrant, so the next step was to investigate Terraform and CloudFormation.
Terraform: Why and How

CloudFormation is coming along nicely, but Terraform had a couple of really compelling features we liked. Namely:
Execution Plans
terraform plan is incredibly useful. Separating planning from execution stages is hands-down Terraform's killer feature. Being able to review what will change before you accidentally terminate an instance with unsaved state (not that that ever happens) can be a lifesaver. Moving fast and breaking things is great and all, but moving fast and not breaking things is, I feel somewhat underrated.
Resource Graph
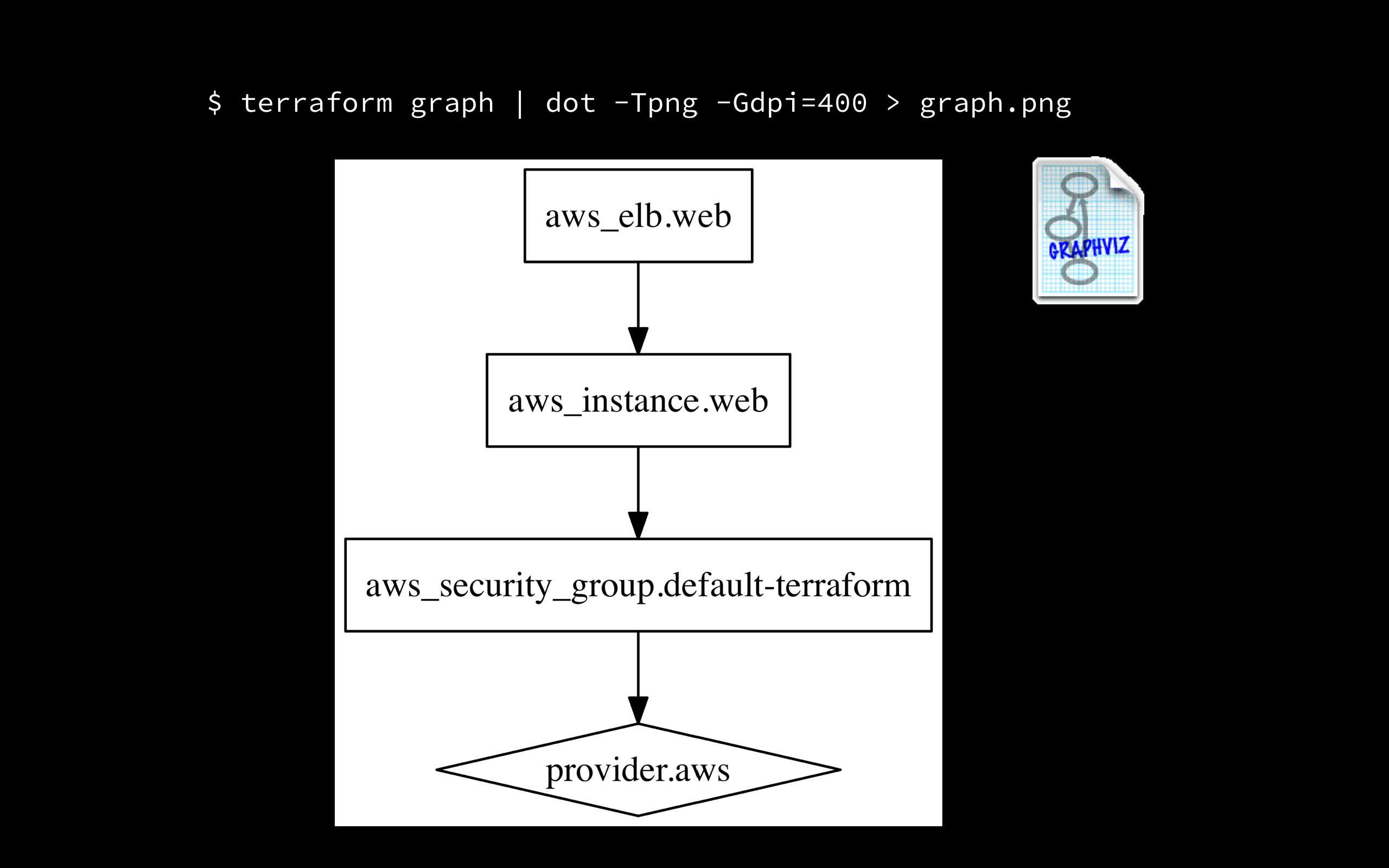
Creating a graph to visualize your infrastructure with terraform is very simple, a one-liner in fact. This can be especially useful to map more complex dependencies and identify network issues that could otherwise be difficult to understand.
Terraform will usually lag slightly behind CloudFormation in terms of AWS feature support, and there are some persistent issues like re-sizing instances requiring complete re-provisioning, but overall the trade-offs have been worth it. The fact that Terraform is provider-agnostic hasn't really come into play for us yet, but it's nice to have the option to use other cloud providers if we'd like to.
Ansible + Terraform together
Using Ansible in conjunction with Terraform has been fairly easy, after running terraform apply, we have a very simple script which uses terraform output to populate an inventory file to pass to Ansible. In some instances, we've been using the Ansible-provided ec2.py to dynamically generate inventory using EC2 tags.
Future work, lessons learned
We have push-button deploys working for several environments but not quite everything. We are still using Capistrano for code deploy though we've made strides toward moving that to Ansible and the early results are promising. We'd also like to speed up our deployment process by building custom Ansible-provisioned AMIs with Packer rather than running Ansible against vanilla Ubuntu AMIs after spinning them up with Terraform. A full Ansible run against vanilla hosts in a given environment, even with command pipelining enabled, tends to take around 15-20 minutes. Doing the Packer builds from our continuous integration environment would yield some obvious wins, of course.
We've come a long way from hand-crafted server-land but there's still plenty of work ahead. By far, the biggest success has been engaging the entire engineering team on infrastructure automation efforts. When we were still using Chef, only a couple of engineers really had any idea how it worked or how to make changes. Today, our automation repository is used by the entire engineering organization - nearly everyone in engineering has commits. As much as the term "DevOps" is misused, this sort of cultural shift is precisely what that should mean. The tools are merely there to support and foster a culture where developers can feel comfortable making changes to infrastructure and a shared sense of ownership of our systems.