
Workflow Schedulers
Workflow schedulers are systems that are responsibile for the periodic execution of workflows in a reliable and scalable manner. Workflow schedulers are pervasive - for instance, any company that has a data warehouse, a specialized database typically used for reporting, uses a workflow scheduler to coordinate nightly data loads into the data warehouse. Of more interest to companies like Agari is the use of workflow schedulers to reliably execute complex and business-critical "big" data science workloads! Agari, an email security company that tackles the problem of phishing, is increasingly leveraging data science, machine learning, and big data practices typically seen in data-driven companies like LinkedIn, Google, and Facebook in order to meet the demands of burgeoning data and dynamicism around modeling. In a previous post, I described how we leverage AWS to build a scalable data pipeline at Agari. In this post, I discuss our need for a workflow scheduler in order to improve the reliability of our data pipelines, providing the previous post's pipeline as a working example.
Scheduling Workflows @ Agari - A Smarter Cron
At the time of the writing of the previous post, we were still using Linux cron to schedule our periodic workflows and were in need of a Workflow (a..k.a. DAG) scheduler. Why? In my previous post, I described how we loaded and processed data from on-premises Collectors (i.e. Collectors that live within on our enterprise customer’s data centers). Cron is a good first solution when it comes to kicking off a periodic data load, but it stops short of what we need. We need an execution engine that does the following :
- Provides an easy means to create a new DAG and manage existing DAGs
- Kicks off periodic data loads involving a DAG of tasks
- Retries failed tasks multiple times to work around intermittent problems
- Reports both successful and failed executions of a DAG via email
- Provides compelling UI visualization to provide insightful feedback at a glance
- Provides centralized logging — a central place to collect logs
- Provides configuration management
- Provides a powerful CLI for easy-integration with automation
- Provides state capture
- for any run, we would like to know the input and configuration used for that run. This is particularly important in the application of models for the purposes of scoring and categorization. As we modify our models, we need a way to track which model versions were used for a particular run both for diagnostic and attribution needs
When using Cron, a developer needs to write a program for the Cron to call. The developer not only needs to write code to define and execute the DAG, he also needs to handle logging, configuration management, metrics and insights, failure handling (e.g. retrying failed tasks or specifying timeouts for long-running tasks), reporting (e.g. via email of success or failure), and state-capture. Soon, every developer is re-inventing the wheel. DAG Schedulers take care of these ancillary needs — the developer just needs to focus on defining the DAG.
Enter Airflow
Earlier this Summer, around the time that I was on the hunt for a good DAG scheduler, Airbnb open-sourced their DAG Scheduler, Airflow -- it met all of our needs above.
DAG Creation
Airflow provides a very easy mechanism to define DAGs : a developer defines his DAG in a Python script. The DAG is then automatically loaded into the DAG engine and scheduled for its first run. Modifying a DAG is as easy as modifying the Python script! The ease with which a developer can get started on Airflow contributes greatly to its draw.
Once your DAG has been loaded into the engine, you will see it on the Airflow home screen. On this page, you can easily hide your DAG from the scheduler by toggling an on/off switch — this is useful if one of your downstream systems is undergoing lengthy maintenance. Although Airflow handles failures, sometimes it’s best to just disable the DAG to avoid unnecessary failure alerts. In the screen shot below, the “cousin domains” DAG is disabled.
DAG Scheduling
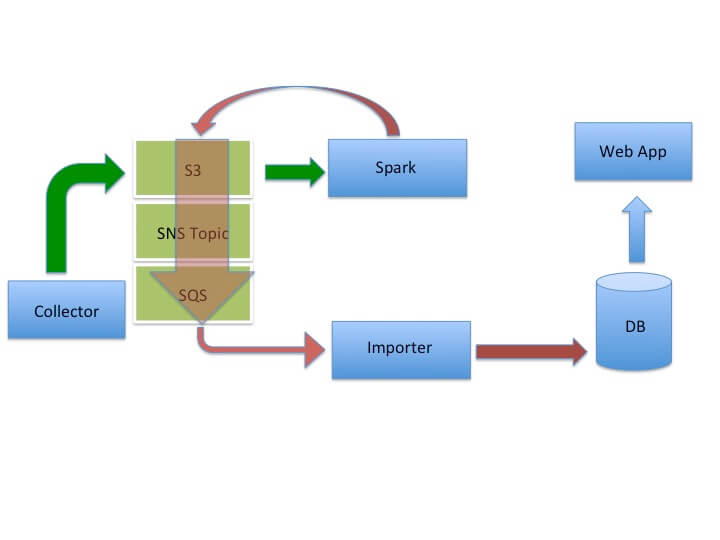
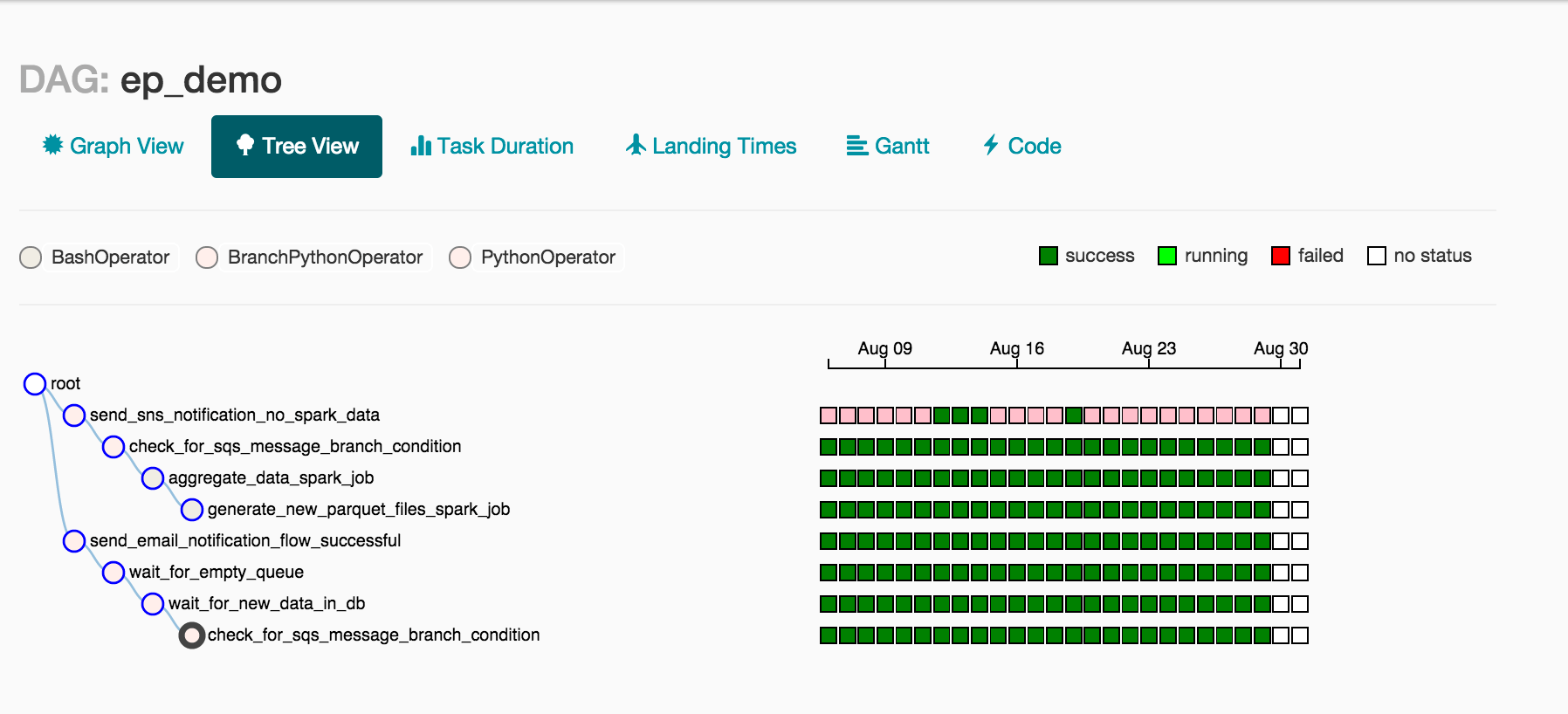
Airflow provides a few handy views of your DAG. The first is the Graph View, which shows us that the run kicks off via the execution of 2 Spark jobs : the first converts any unprocessed collector files from Avro into date-partitioned Parquet files and the second runs aggregation and scoring for a particular date (i.e. the date of the run). As the second Spark job writes its output to S3, S3 "object created" notifications are sent to an SQS queue!
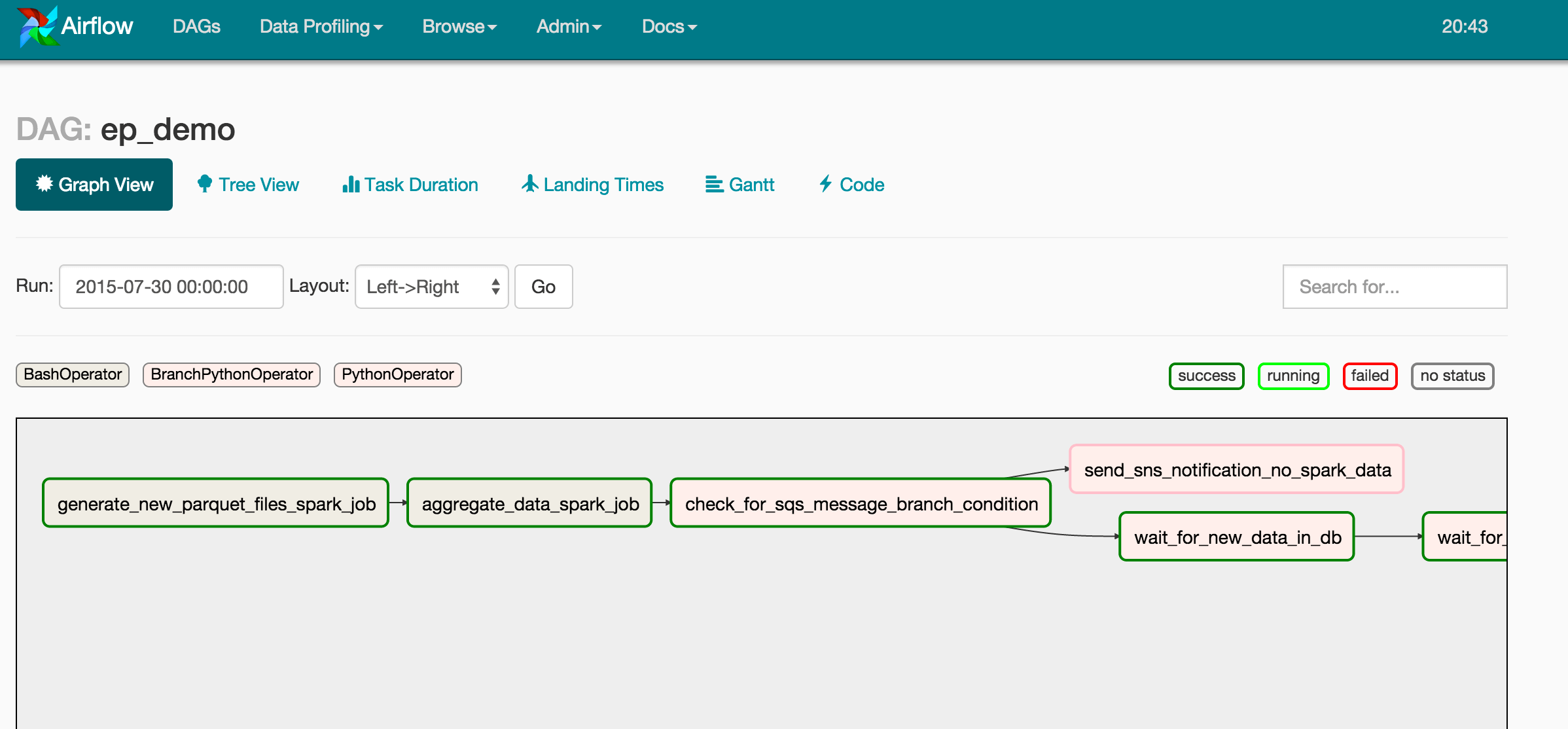
The next task (i.e. check_for_sqs_message_branch_condition) provides a very cool feature not present in other DAG Schedulers — a Branch Condition Task. This task type allows execution to proceed down one of various paths in the DAG for a particular run. In our case, if we check and find no data in SQS, we abandon further downstream processing and send an email notification that data is missing from SQS! If all is well and messages do show up in SQS, we proceed down the main line of our pipeline! This involves a few more tasks :
- wait_for_new_data_in_db
- ensure that newly generated data is being successfully written to the db
- wait_for_empty_queue
- wait for the SQS queue to drain
- send_email_notification_flow_successful
- query the DB for the count of records imported
- send the counts in a “successful” email to the engineering team
Over time, we can quickly assess the run status for multiple days by referring to Airflow's Tree View. In the image below, a vertical column of squares relates to all of the tasks in a day’s run of a DAG. For July 26, the run completed successfully because all squares are forest green!
Airflow Command-line Interface
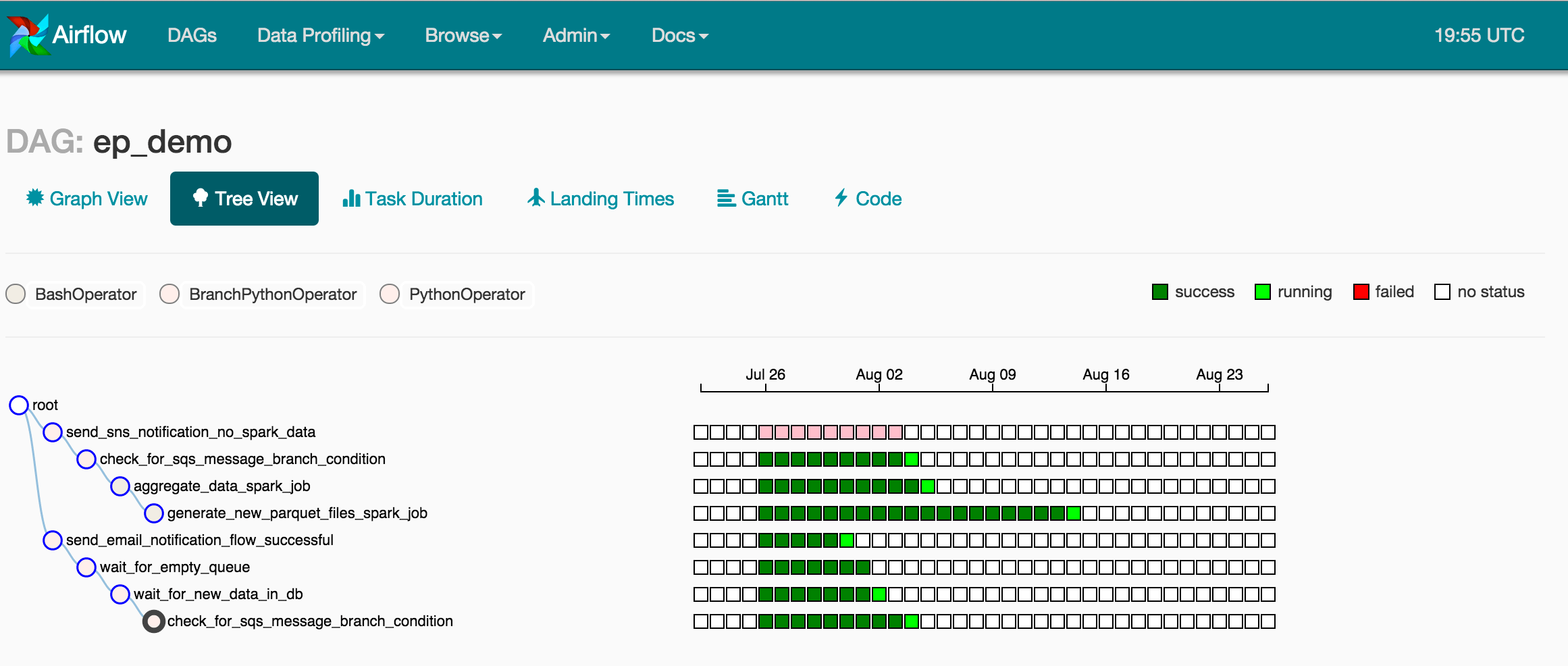
Airflow also has a very powerful command-line interface, one that we leverage in automation. One powerful command, “backfill”, allows us to re-run a DAG over a set of days. In the Tree View below, we observe a 30-day backfill in progress. Some days are complete (e.g. July 26-30), some are in progress (e.g. July 31, Aug 1, Aug 2, Aug 3), and some have not been scheduled yet (e.g. Aug 16). Airflow executes tasks in parallel when it can, based on the DAG definition and optional time-precedence rules (e.g. a previous day’s task must be successful before executing the current day’s run)
DAG Metrics and Insights
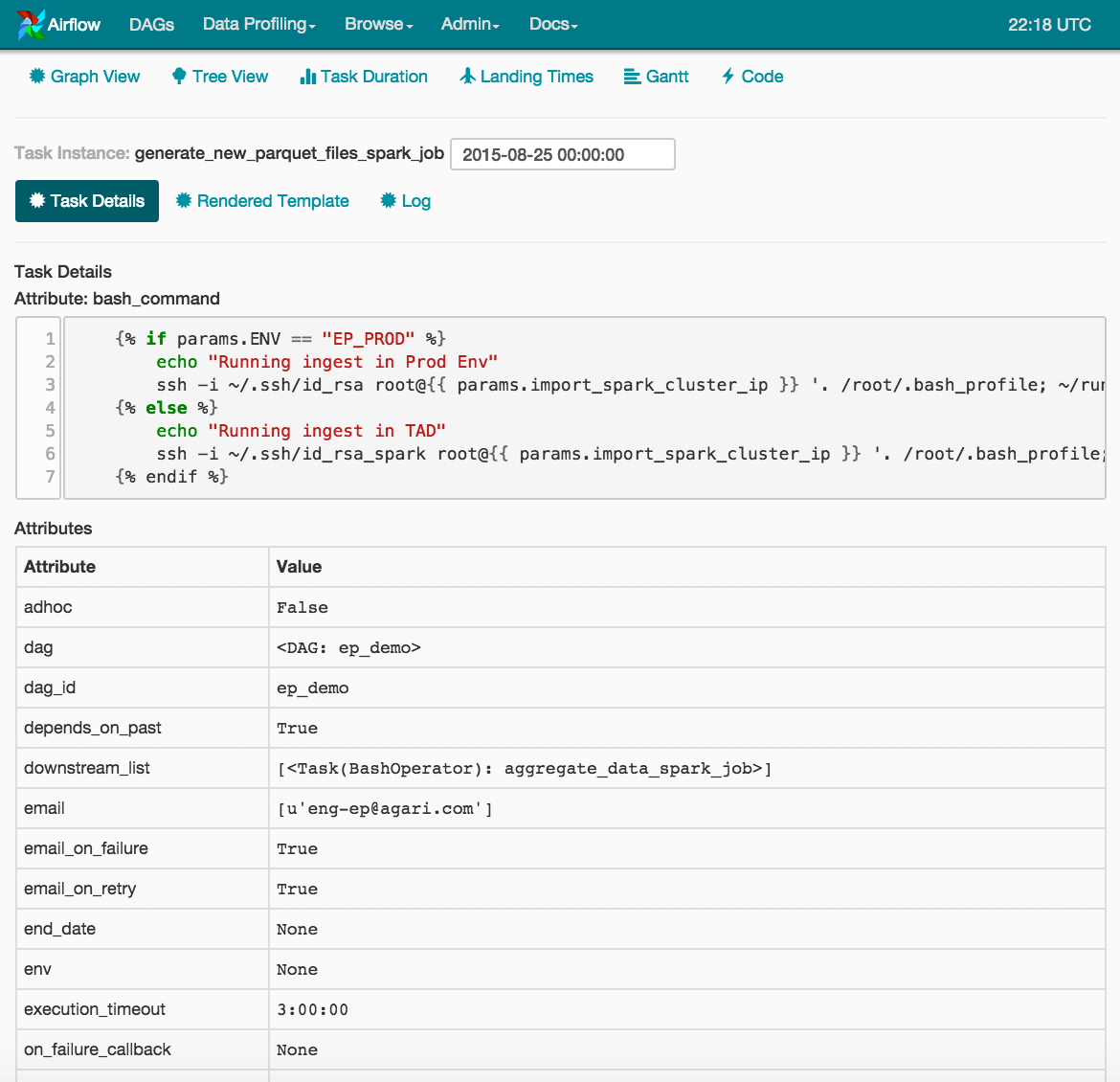
For every DAG execution, Airflow captures the run state, including any parameters and configuration used for that run and provides this run state at your finger tips. We can leverage this run-state to capture information such as model versions for different versions of machine-learned models that we use in our pipeline. This helps us in both issue diagnosis and attribution.
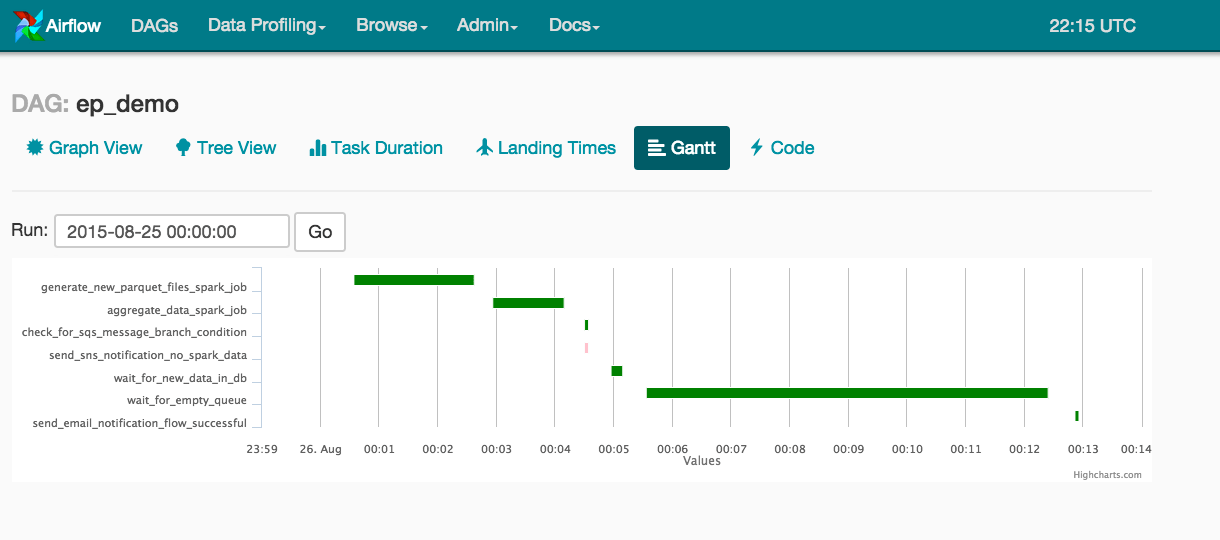
In terms of pipeline execution, we care about speeding up our pipelines. In the Gantt chart below, we can view how long our Spark jobs take in hopes of speeding them up. Additionally, our wait_for_empty_queue phase can be sped up by more aggressive auto-scaling (i.e. via AWS Auto-Scaling Groups). For example, we scale out the importers 4-at-a-time, but if we scale them out 8-at-a-time or increase the max ASG pool size from 20 to 40, we can reduce the time spent in this stage of our pipeline.
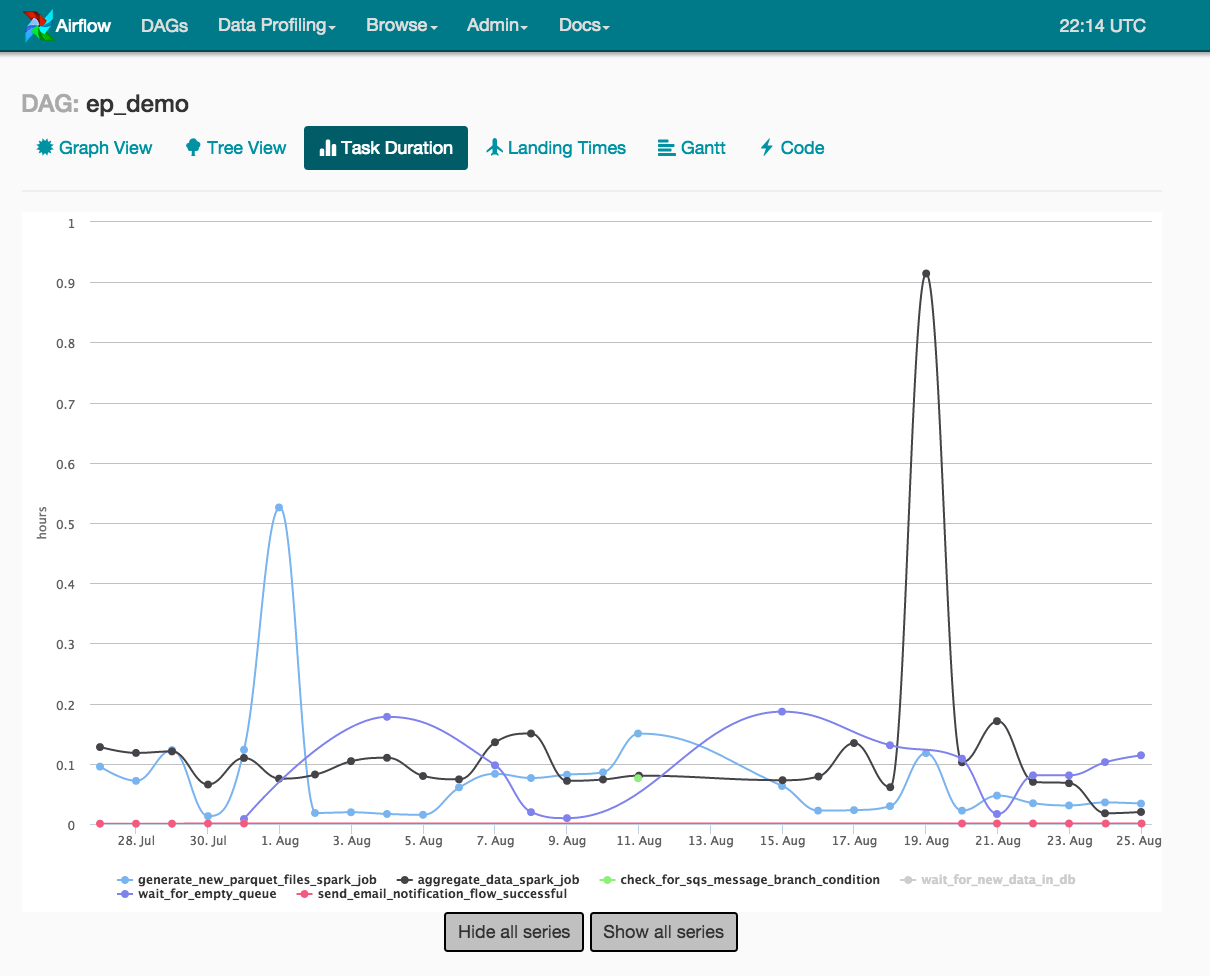
We also care about the time variability of runs. For example, will a run always take 30 minutes to complete or does the time vary wildly? As shown in the Task Duration chart, two of our stages, the two spark jobs, have large time variability. The time variability in these 2 tasks results in large time variability in our overall job completion times. Hence, this chart clearly tells us where we should spend time in terms of speed and scalability enhancements in order to get more predictable run times. Once we solve that problem, we can consider turning on another Airflow feature : SLAs (Service-level Agreements).
DAG Configuration
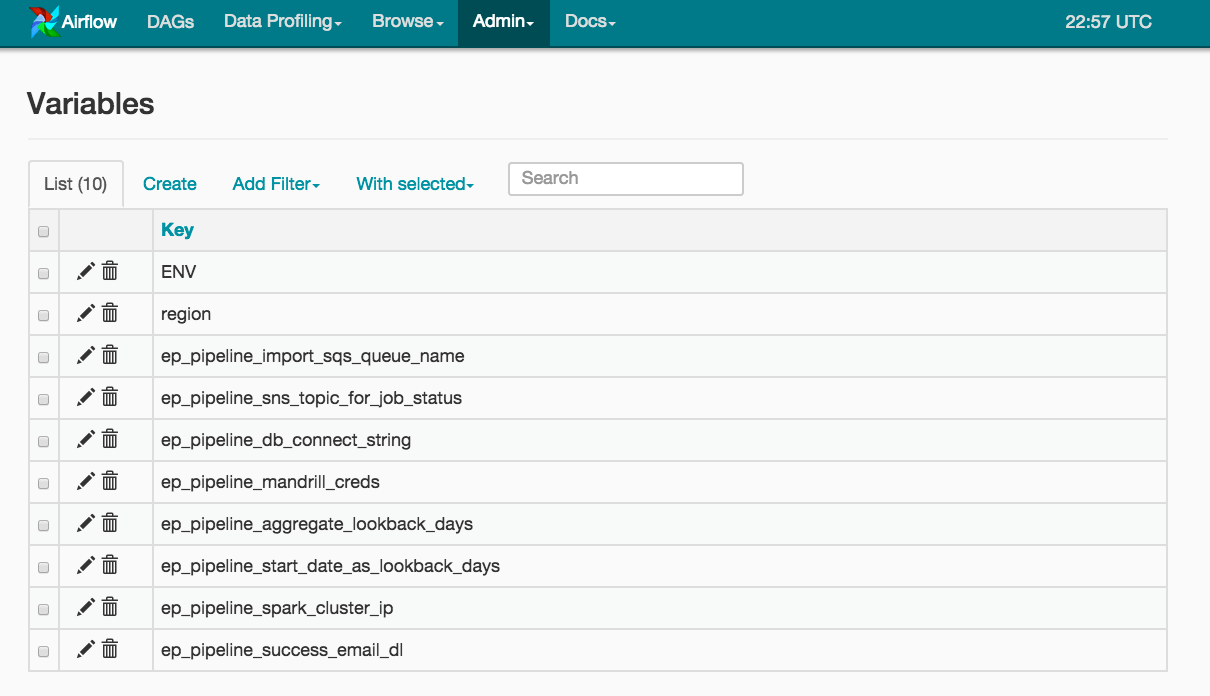
Another handy feature of Airflow are Variables. Variables allow us to feed environment-specific (e.g Prod, QA, Dev) configuration via an Admin screen to our DAGs. This takes the config out of our Git repo and places it squarely in the UI and Airflow Metadata DB. It also allows us to make changes on-the-fly without checking changes into Git and waiting for deployments.
Other Cool Features
Airflow allows you to specify tasks pools, task priorities, and a powerful CLI, which we leverage in automation.
Why Airflow
Airflow is easy to set up (e.g. via pip install if you only want releases) as an admin. It has a terrific UI. It is developer friendly since it allows a developer to set up a simple DAG and test it in minutes. How does it compare with leading solutions such as Spotify’s Luigi, LinkedIn’s Azkaban, and Oozie? Having previously worked at LinkedIn and used Azkaban, I wanted a DAG scheduler with good UI functionality, at least on par with Azkaban's. The UI in Spotify’s Luigi is not very useful. However, Azkaban requires some build automation to package even relatively simple DAGs into a zip file — the zip file zips a directory that contains a tree-structured representation of code and config. Modifying a DAG requires hopping through the tree of config. Oozie, at least when I last used it, required DAG definitions in an XML file — this made even simple DAGs a nightmare to grok. Spotify’s Luigi and Airbnb’s Airflow both provide DAG definition in a single file — both leverage Python. An additional requirement was that the DAG scheduler be cloud-friendly. Since, both Luigi and Airflow were born in the cloud, that was one less headache to worry about. In short, I wanted the UI sophistication of Azkaban and the cloud-friendliness and the DAG management and definition ease of Luigi — Airfbnb’s Airflow was that right mix.
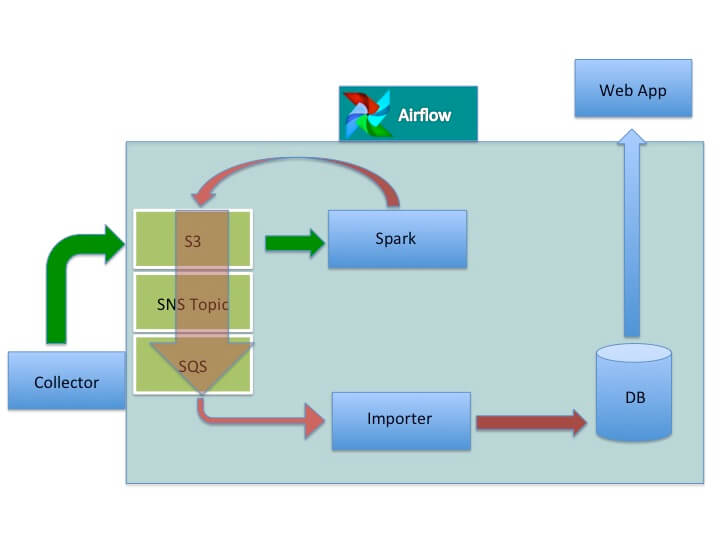
Our revised architecture is shown below.
Caveats
It is important to mention that Airflow, which was only open-sourced a few months ago, is still a work in progress. It has a lot of promise, a dedicated and capable team, and a small but growing community. As an early adopter, Agari is committed to making this a successful project, either by tripping over bugs and reporting them, suggesting features and enhancements, and by contributing to the code base.